意見詞提取作為方面級情感分析(Aspect-based sentiment analysis, ABSA)的一個關鍵子任務,旨在從文本中辨別與特定方面相關聯的意見詞。早期意見詞提取工作主要集中在如何手動提取經過細化的特征,并將這些特征輸入到支持向量機等分類器中,后來一些研究人員開始采用自動特征提取方法實現意見詞提取,例如,通過句法關系自適應地將上下文詞中的情感傳播到方面項。其他則構建了一個無需進行句法分析的特征提取器,以識別指定方面的相關特征。隨著深度學習技術發展,為更進一步進行語義建模,有文獻提出使用與目標相關的長短期記憶網絡(Long short-term memory,LSTM)來進行自動特征提取。HE等則將注意力機制(Attention mechanism,AM)與LSTM結合應用于方面級情感分析,以聚合上下文特征進行意見詞提取。此外,為了更好關注單詞間的句法聯系,處理更復雜的句子結構,一些研究也開始將依存句法樹、成分句法樹和意見句法樹等句法樹引入到意見詞提取中。
從食品品評文本中進行感官分析與上述意見詞提取研究類似,兩者都需要從文本中自動提取出與某一方面相關的特征描述詞,并分析這些詞與方面之間的關系。因此,意見詞提取中的一些技術和方法可以為食品感官分析提供啟發和支持。不過,在食品感官分析領域,感官信息既包括甜、酸、苦、咸等基本味道,也包含質地、口感潤滑度、粘稠度等多方面信息;同時每一種感官信息都有自己的強度屬性。例如某一款飲料的甜度較強,但是酸度較弱,在這種情況下僅提取出酸和甜無法細粒度刻畫其感官評價。這導致已有的意見詞提取研究難以直接應用在食品感官分析領域,無法直接捕捉食品感官評價中的感官詞及對應的感官強度、難以對感官強度進行細粒度處理。
本文旨在針對食品品評文本進行細粒度感官分析,基于方面級意見提取提出一種基于強度注意力和強度句法樹的細粒度感官分析模型FGSAM-01,構建專用的食品感官分析數據集,并在該數據集上對模型進行實驗驗證。
細粒度感官分析模型描述
為了更好挖掘食品品評文本實現對食品感官的細度分析,本文提出一種細粒度感官分析模型FGSAM-01。在FGSAM-0I中,提出一種強度注意力動態調整對輸入序列不同部分的關注程度以進一步強化對強度詞的表示能力;同時,提出強度句法樹進一步將強度詞關聯到相應感官詞,以更準確描述感官詞與強度詞關系,進而從整體上提升食品各個方面感官屬性的分析精確度,圖1展示了FGSAM-0l的整體框架,主要由4部分組成:文本編碼模塊,用于對輸入的食品品評文本序列進行編碼;強度注意力模塊,用于強化對文本序列中強度詞的表示;強度句法樹融合模塊,用于分析強度詞和感官詞的關聯性;分類器,將強度詞轉化成對應的強度數值。
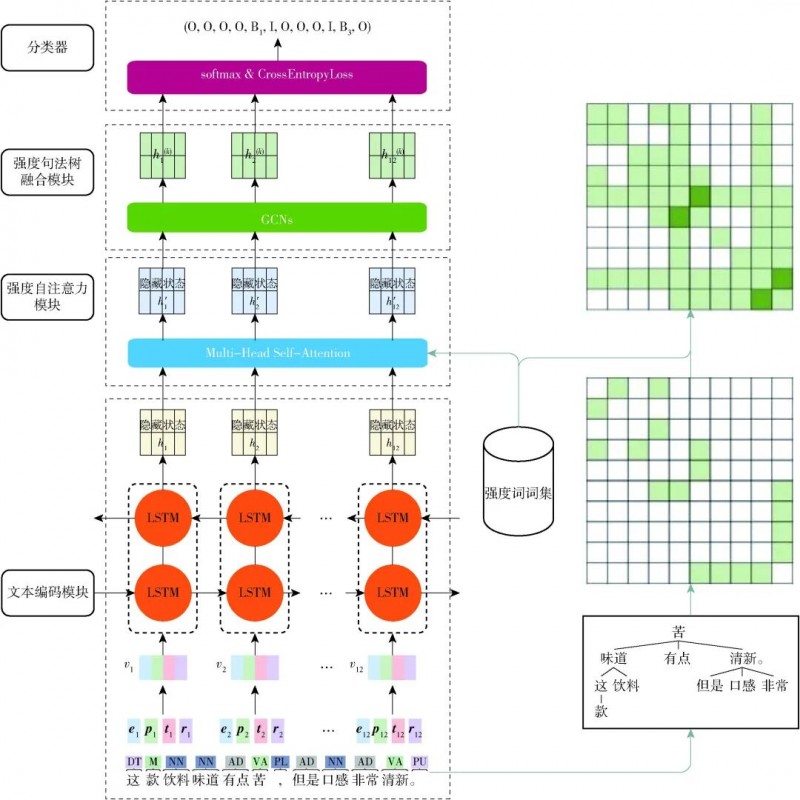
01問題定義
對于給定的食品品評數據集,每一個數據樣本可以表示為S={w1,w2,…,wn},其中n為句子中的token數,每個句子會有一個或多個方面項wasp∈S,對某個方面項可以通過B/I/O標注方式提取句子中的感官詞wopn∈S,并以B0、B1、B2和B3表示wopn的感官強度,分別代表無感官強度和低、中、高感官強度。
02文本編碼模塊
文本編碼模塊的任務是將數據集中的品評文本轉化為相應的向量表示,以便后續模型處理。對一個包含n個token的句子S,從詞嵌入、位置嵌入、詞性嵌入和依賴關系嵌入4個方面對其進行文本嵌入,以更全面建模和理解輸入的品評句子。
03強度注意力模塊
為進一步實現細粒度感官分析,提取品評文本中的感官詞及其相應強度信息,借鑒深度學習中的多頭注意力機制,本文提出在模型中增加強度注意力模塊。該模塊通過反向傳播學習權重矩陣動態調整對品評文本中不同詞的關注程度,以進一步強化對強度詞的關注,提高分析準確率。
04強度句法樹融合模塊
在通過強度注意力模塊提高對強度詞關注程度后,為更好借助句法結構將感官詞和強度詞進行關聯,本文基于傳統的依存句法樹設計一種強度句法樹(lntensity syntax tree),根據預定義的強度詞集合,對與強度詞相關的依存關系進行加權處理。05分類器在模型最后階段,本文采用了與文獻類似的方法進行分類與優化。模型首先將最后一層GCN的輸出表示H應用于線性層,然后使用softmax函數對其進行標準化,以輸出S中每個token在集合{B,I,O}上的概率分布以及強度。在訓練過程中,通過使用交叉熵損失函數來最小化訓練集中文本的預測誤差。
最終,模型會輸出格式為[[BeginIndex, EndIndex], Intensity]的結果,分別標識感官詞及其強度詞的起始和結束位置以及具體的感官強度。通過將這些預測結果與特定的方面進行關聯,并進行匯總與分析,即可得到最終的食品感官分析結果。
實驗數據集
本文以北京林業大學生物學院的風味碳酸飲料PM&FP(Project mapping & Flash profile)感官調研結果為基礎,構建了專有的食品感官分析數據集。該數據集總共包含180名消費者共1 127條有效評論品評文本,按照3∶1的比例劃分為訓練集和測試集。具體的數據集特征見表3。在對品評文本進行數據標注時,文本分詞、句法解析以及詞性標注均通過Stanford CoreNLP完成,而方面詞、感官詞和感官強度則由實驗人員手工標注以支撐模型訓練和測試。
同時,本文將感官詞和強度詞的提取任務定義為序列標注任務,并改進了原有的BIO標注以標識強度信息。具體來說,會將句子中的token標記為感官詞的開始(B0、B1、B2、B3分別代表無強度信息和低、中、高強度信息)、中間或結尾(I),或者不是感官詞(O)。數據集標注示例見表4。
更多精彩內容請見《基于細粒度方面級意見提取的食品感官分析研究(下)》!


